| Слова (леммы) | 177 534 |
|---|---|
| Словоформы | 5 484 057 |
| Клаузулы | 303 187 |
Основная компонента Rhymes – словарь рифм – был создан на основе Грамматического словаря русского языка А. А. Зализняка, который содержит базовые словоформы ~110 тыс. слов с полным морфологическим описанием (в том числе схемами ударений).
Для каждой словоформы в словаре хранится информация о части речи. Для краткости определены следующие части речи: существительные (сущ.), прилагательные (прил.), местоимения (мест.), глаголы (глаг.), причастия (прич.), деепричастия (деепр.), числительные (числ.), наречия (нареч.) и служебные (служ.).
Предположительные и затруднительные в образовании словоформы (например, ед. число краткой формы прилагательных на -ский, множ. число от дно и т. п.) в словарь не включались.
Наречия в словаре Зализняка представлены очень выборочно, поскольку большую долю составляют наречные прилагательные (темно, легко, красиво и т. п.). Мы продублировали ~ 1 тыс. кратких форм прилагательных в классе наречий.
Для версии 3.6 был существенно переработан модуль морфологического синтеза всех акцентуированных словоформ. Теперь этот модуль качественно образует парадигмы как с регулярным, так и с нерегулярным словоизменением (ребёнок – мн. дети, быть – 1 л. ед. есть). В том числе теперь правильно склоняются составные слова (баба-яга) и включаются все формы с вариативным ударением (базилика ⇒ базилика и базилика).
В отличие от предыдущих версий Rhymesдля генерации Словаря рифм теперь мы используем дополненное и исправленное 4-е издание ГСЗ (2003 г., ~10 тыс. новых слов в основной части словаря и ~8 тыс. имен собственных из Приложения). Так что Словарь рифм теперь содержит имена (полные и уменьшительные), отчества, распространенные фамилии, топонимы, названия организаций и т. п. – всем этим словам соответствует "краткая" часть речи: существительные собственные с. сущ. (С). Мы также дополнили этот список автоматически синтезированными вариантами уменьшительных (т. н. гипокористических) имен (~4 тыс. слов).
В версии 3.6 мы задействовали еще один механизм пополнения Словаря рифм – предсказание грамматических характеристик слов, отсутствующих в ГСЗ. В качестве источника новых слов были использованы частично грамматизированные списки заглавных слов с ударениями из Большого толкового словаря (входящего в состав Rhymes), Орфографического словаря под ред. В. В. Лопатина (2004), а также небольшой список современной околокомпьютерной лексики, составленный нами вручную. Отфильтровав все неоднозначно предсказанные слова, мы получили почти 50 тыс. новых лемм для пополнения исходного Словаря Зализняка.
Конечно, в новом лексическом массиве содержится некоторое количество слов, парадигмы которых предсказаны неверно (не более 1-2%). Поскольку мы не анализируем контекст употребления слов, ряд грамматических свойств (например, одушевленность у существительных или переходность у глаголов) предсказываются неуверенно. Постепенно мы будем вычищать эти ошибки как улучшением алгоритмов, так и вручную. Надеемся на вашу помощь в этом процессе.
Итог этих работ таков. Словарь рифм пополнился на 75 тыс. слов (1,6 млн. словоформ), среди которых есть как редкие слова (по большей части специализированные термины), так и частотные слова, недавно вошедшие в употребление. Кроме того рифмовник теперь включает почти 12 тыс. имен собственных (230 тыс. словоформ).
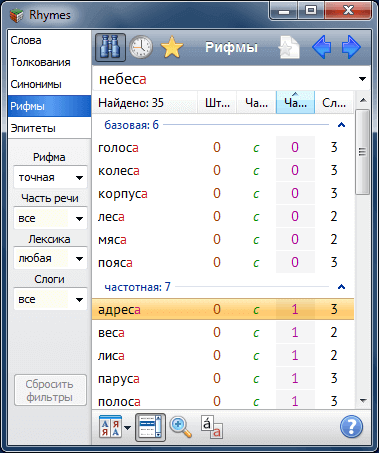
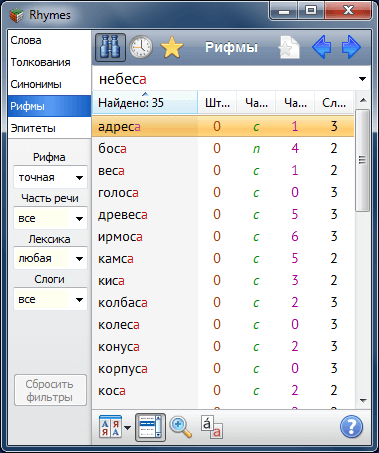
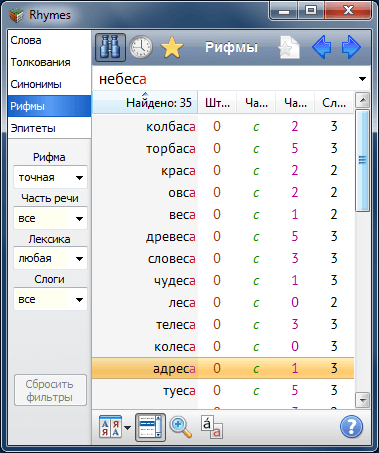
Поиск рифм в словаре ведется только среди слов, клаузулы которых имеют то же количество слогов и ту же ударную фонему, что и у шаблонного слова (гонять – гнать [а] в отличие от гнуть – гнать).
Качество рифмовки 2-х слов оценивается фонетическим сравнением их клаузул и предударного звука. Графическая запись слова переводится в фонетическую транскрипцию на основе правил произношения и Орфоэпического словаря, входящего в состав Rhymes. Так, например, к слову браться находится точная рифма братца (род. п. от братец). Основные типы фонетических различий наделены некоторыми весами. Собственно качество рифмовки оценивается штрафом – суммой реализаций этих весов. Чем выше штраф, тем хуже рифма. Точная рифма соответствует штрафу = 0.
В программе есть два способа отобрать рифмы требуемого качества: либо задать диапазон значений штрафов рифм, либо выбрать вариант качества (рифма точная, богатая, средняя, грубая) из выпадающего списка. При выборе варианта "любая" выводятся все рифмы от точных до грубых, при этом цвет (яркость) слова визуально отражает качество рифмы (только в режимах отображения "В строку" или "Колонки"). Переключение между разными видами фильтра качества выполняется кнопкой "Рифмы / Штраф". Изменять качество также можно с помощью клавиш Num+ и Num−.
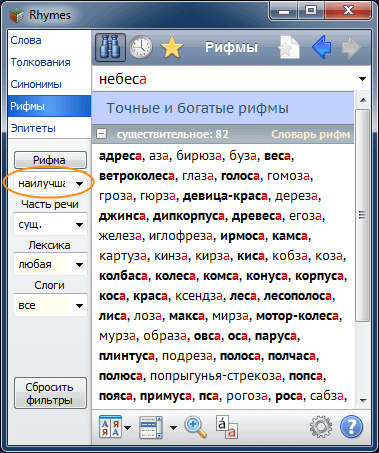
В версии 3.7 введен еще один вариант качества — адаптивный (наилучшая рифма). Он позволяет для произвольного набора фильтров динамически подбирать рифмы наилучшего качества. Если имеются точные рифмы, но их мало, в список включаются также богатые рифмы. Если нет ни точных, ни богатых рифм, автоматически показываются средние рифмы и т.д. Данный режим очень удобен для быстрого подбора рифмы к слову, поскольку сводит к минимуму действия с фильтром качества. Фильтрация адаптивным качеством теперь по умолчанию применяется при вводе нового слова-запроса. Изменить умолчания можно в Настройках.
Без прототипа модуля морфологического синтеза, который был любезно предоставлен Максимом Ушаковым, этот проект навряд ли получил бы продолжение. Автор также выражает глубокую признательность Борису Смилге и Сергею Анатольевичу Старостину за электронный вариант Грамматического словаря Зализняка, Сергею Шарову и Сергею Слепову за варианты частотных словарей. Отдельная благодарность команде проекта AOT – Алексею Сокирко, Дмитрию Панкратову, принимавшим активное участие в сравнении морфологий Зализняка и Dialing.